SpindelCheck
Status Quo
Die derzeitigen Wartungspraktiken für Spindeln bei SEW sind hauptsächlich reaktiv und präventiv ausgelegt und verfügen nicht über fortgeschrittene Predictive-Maintenance-Fähigkeiten. Spindelausfälle führen häufig zu ungeplanten Produktionsstillständen, beeinträchtigen die Betriebseffizienz und erhöhen die Wartungskosten.
In den letzten zehn Jahren hat SEW IFM-Sensoren in Verbindung mit der IFM Moneo-Plattform für die manuelle Spindelüberwachung eingesetzt.

Diese Lösung liefert zwar wertvolle Daten, erfordert jedoch erhebliche manuelle Eingriffe und ermöglicht keine automatisierte Früherkennung potenzieller Ausfälle.
Die aktuellen Wartungsstrategien umfassen:
- Geplante vorbeugende Wartung in festen Intervallen
- Reaktive Reparaturen nach Spindelausfällen
- Manuelle Inspektionen und Diagnosetests
Diese Ansätze bringen mehrere Herausforderungen mit sich:
- Unerwartete Ausfallzeiten aufgrund unerkannter Spindelprobleme
- Suboptimale Zuteilung von Wartungsressourcen
- Eingeschränkte Fähigkeit zur genauen Schätzung der verbleibenden Nutzungsdauer (RUL) von Spindeln
Ein Übergang zu vorausschauender, datengesteuerter Wartung ist erforderlich, um diese Einschränkungen zu beheben und die Gesamtzuverlässigkeit der Anlagen zu verbessern.
Ziel
Implementierung einer IIoT-basierten Predictive-Maintenance-Lösung zur Spindelüberwachung mit folgenden Zielen:
- Erfassung hochauflösender Sensordaten für die Spindelzustandsanalyse, idealerweise unter Verwendung vorhandener Sensoren
- Kontinuierliche Überwachung des Spindelzustands
- Implementierung von Anomaly Detection und Ausfallvorhersage
- Reduzierung ungeplanter Ausfallzeiten durch Frühwarnsystem
- Schaffung der Grundlage für einen potenziellen flächendeckenden Rollout und robuste Predictive-Maintenance-Strategie
- Optimierung der Wartungspläne basierend auf dem tatsächlichen Zustand
- Bereitstellung umsetzbarer Erkenntnisse über eine benutzerfreundliche Schnittstelle
Stand der Technik
Es gibt viele bestehende AI / Machine-Learning-Ansätze zur Überwachung rotierender Maschinen und zur Vorhersage von Ausfällen:
| Ansatz | Beschreibung | Automatisierungsgrad | Analytics | ML/AI Nutzung |
|---|---|---|---|---|
| Traditional Condition Monitoring | Periodische Vibrationsanalyse mit Handmessgeräten | Manuell | Einfach (Stichproben) | Keine |
| Continuous Monitoring Systems | Installierte Sensoren mit einfachen Schwellenwert-Alarmen | Halbautomatisiert | Schwellenwertbasierte Alarme | Keine |
| AI-based Predictive Maintenance | ML-Modelle trainiert auf historischen Ausfalldaten | Automatisiert | Predictive Analytics | Supervised & Unsupervised ML |
AI-based Predictive Maintenance nutzt tendenziell die meisten Signale zur Vorhersage von Ausfällen, darunter:
- Vibrationsanalyse (Frequency Domain Analysis, FFT)
- Temperaturüberwachung
- Akustische Emissionsmessung
- Strom-/Leistungsüberwachung
- Machine Learning für Anomalieerkennung
- Remaining Useful Life (RUL) Vorhersage
Von diesen ist Vibration das dominierende Signal für die Spindelgesundheit. Die erfolgreichsten RUL-Systeme basieren auf Beschleunigungssensordaten (rohe Zeitreihen plus Envelope / Spectral Transforms). Time-Domain-Statistiken (RMS, Kurtosis) und Envelope-Spectrum-Features werden nach wie vor häufig als starke, interpretierbare Indikatoren verwendet.
Time-Frequency-Representations & CNNs sind ein sehr effektiver Pattern-Recognition-Ansatz. Die Umwandlung von Fenstern in STFT/CWT/Spectrogram-Images und das Training von CNNs (oder CNN → LSTM Hybrids) liefert starke Performance bei Bearing/Spindle-Aufgaben, insbesondere beim Umgang mit komplexen Vibrationssignaturen. Neuere Ansätze kombinieren CNNs mit Sequence Models (Bi-LSTM) oder Variational Autoencodern für robuste Feature Extrahierung.
Recurrent Models werden weiterhin häufig eingesetzt. Sequence Models (LSTM / Bi-LSTM / Transformers) behandeln temporale Abhängigkeiten gut. Transformers und Wavelet-Self-Attention-Hybrids werden für längere Abhängigkeiten und Cross-Sensor-Fusion erforscht und übertreffen LSTMs in Benchmarks oft, wenn genügend Daten verfügbar sind.
State-of-the-Art-Arbeiten kombinieren zunehmend Methoden (z.B. CNN → Transformer, CNN + VAE + BiLSTM), um starke lokale Feature Extraction mit temporaler Modellierung und Unsicherheitsschätzung zu verbinden. Diese Hybrids schneiden bei komplexen Multi-Sensor-Datensätzen tendenziell am besten ab.
| Phase | Ziel |
|---|---|
| Datenvorbereitung & Qualitätsbewertung | Daten verstehen und bereinigen |
| Datenstrukturierung & Failure Mapping | Daten organisieren, RUL definieren |
| Feature Exploration & Signal Validation | Auf prädiktive Degradation prüfen |
| Feature Engineering | Aussagekräftige Input-Features erstellen |
| RUL Modeling | Modelle trainieren, validieren und interpretieren |
| Auswertung & Präsentation | Machbarkeit und Ergebnisse zusammenfassen |
Mögliche Entwicklungsphasen einer Predictive-Maintenance-Lösung
Lösungsvorschlag
Um die Predictive-Maintenance-Lösung in die bestehenden Systeme von SEW zu integrieren, werden Sensordaten in eine Analytics-Plattform eingespeist, wo Preprocessing, Feature Extraction und Machine-Learning-Algorithmen angewendet werden.
Zur Erfassung hochauflösender Daten bis zu 100 kHz, die für fortgeschrittene Vibration Analysis benötigt werden können, wird Motius direkte Verbindungen zu IFM-Sensoren über industrielle Protokolle (z.B. OPC-UA, MQTT, Modbus, Serial Connection) untersuchen, sofern unterstützt, oder Edge-Computing-Geräte nutzen, um rohe Sensordaten zu erfassen und abzuspeichern.
Alternativ könnte der vorhandene VSE100 kurze Bursts von rohen Daten bei hohen Sampling-Raten aufzeichnen, die dann periodisch getriggert und zur Analyse abgespeichert werden können.
Falls direkter Hochfrequenz-Datenzugriff mit IFM-Sensoren nicht machbar ist, wird das Team Montronix-Sensoren evaluieren.
Zusätzliche Hardware kann bei Bedarf in Betracht gezogen werden, um die Data-Acquisition-Anforderungen zu erfüllen.
Um sicherzustellen, dass die erfassten Daten für die beabsichtigten Analysen geeignet sind, wird das Projektteam eng mit SEW zusammenarbeiten, um sicherzustellen, dass Sensorplatzierungen, Konfigurationen und Datenqualität den Anforderungen der Predictive-Maintenance-Modelle entsprechen. Dies kann die Validierung von Sensorkalibrierung, Sampling-Raten und Datenintegrität sowie die Definition von Messverfahren umfassen.
Daten werden entweder on-premise bei SEW, oder in SEW's Microsoft Fabric Umgebung abgespeichert.
Prozessintegration
In der Explorationsphase wird das Projektteam eng mit SEW zusammenarbeiten, um aktuelle Prozesse zu verstehen und Integrationspunkte für Predictive-Maintenance-Fähigkeiten zu identifizieren.
Das Projektteam wird die bestehenden Wartungsprozesse von SEW abbilden, um Folgendes zu identifizieren:
- Geplante Wartungsintervalle und Entscheidungskriterien
- Reaktive Wartungsauslöser und Reaktionsverfahren
- Datenquellen, die derzeit für Wartungsentscheidungen verwendet werden (manuelle Inspektionen, Moneo-Alarme, Wartungsprotokolle)
- Wichtige Stakeholder und Kommunikationskanäle
- Dokumentations- und Berichtsanforderungen
Datenerfassung
Parallel zur Prozessbewertung evaluiert das Projektteam die Datenerfassung von IFM und / oder Montronix-Sensoren. Das Team wird validieren, dass die gesammelten Daten eine ausreichend hohe Auflösung und Qualität bieten.
Pilotsystem
Ein Pilotsystem wird parallel zu bestehenden Prozessen entwickelt und läuft nebenher, ohne größere Änderungen zu erfordern:
- Data Recording: Einige Maschinen mit IFM / Montronix-Sensoren werden ausgestattet, um kontinuierlich rohe Sensordaten aufzuzeichnen und abzuspeichern (on-premise oder Cloud, in Absprache mit SEW's IT)
- Parallel Validation: Predictive Insights werden mit Wartungsteams zur Validierung gegen tatsächliche Spindelbedingungen geteilt, lösen aber während des PoC keine direkten Wartungsaktionen aus
- Feedback Loops: Regelmäßige Kollaborationssitzungen zum Vergleich von Modellvorhersagen mit beobachtetem Spindelverhalten und Wartungsergebnissen
- Alert Refinement: Iterative Anpassung der Detection-Sensitivität basierend auf operativem Feedback, um False Positives zu minimieren und gleichzeitig sicherzustellen, dass kritische Probleme erkannt werden
Übergangsplanung
Basierend auf den Erkenntnissen aus dem Pilotsystem wird gemeinsam mit SEW definiert:
- Wie Predictive Alerts in die bestehende Wartungsplanung integriert werden sollen
- Rollen und Verantwortlichkeiten für das Monitoring und die Reaktion auf System-Insights
- Erforderliche Dokumentation für Wartungspersonal
- Integrationspunkte mit bestehenden IT-Systemen
- Eskalationsverfahren für kritische Alarme
Dieser kollaborative Ansatz stellt sicher, dass die finale Lösung mit den operativen Realitäten von SEW übereinstimmt und mit minimaler Störung übernommen werden kann.
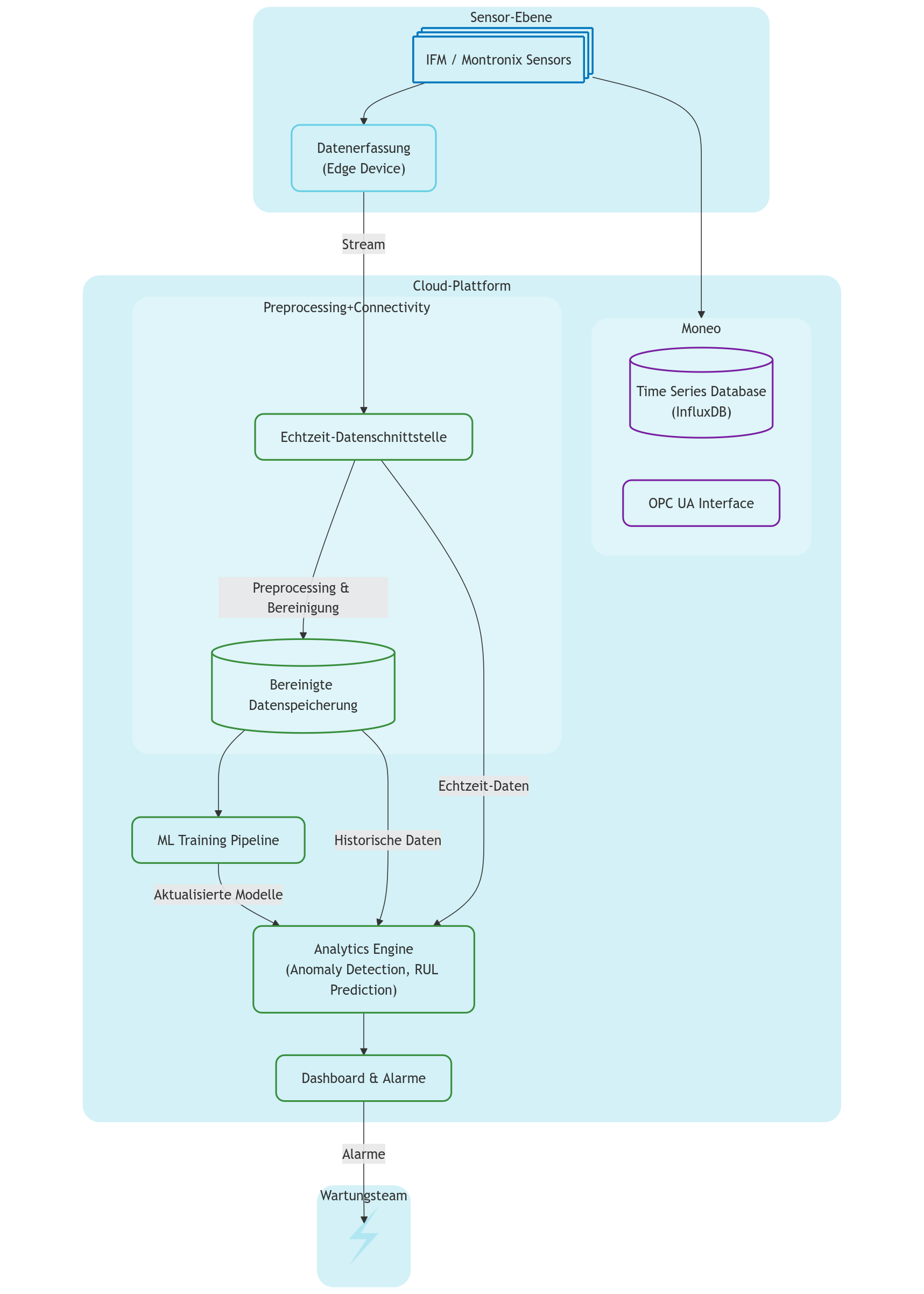
Systemkonzept
Die Systemarchitektur besteht aus drei Hauptebenen:
- Sensoren & Data Acquisition
- IT Software Platform
- User Interface für die Wartung
Während die Sensor-Hardware die Grundlage der Datenerfassung bildet, ist die IT Platform für Datenspeicherung, Preprocessing und fortgeschrittene Analytics verantwortlich. Das User Interface zeigt Alarme und Ergebnisse der Vorhersagen aus unserem Modell, vor allem für SEW's Wartungsteam.
graph TB
%% Styles
classDef primary fill:#64CEE4,stroke:#64CEE4,stroke-width:2px,rx:10px
classDef default fill:none,stroke:#64CEE4,stroke-width:2px,rx:10px
classDef defaultBackground fill:#FFFFFF44,stroke:none,rx:20px
classDef primaryBackground fill:#23BAD933,stroke:none,rx:20px
subgraph sensorSub["Sensor-Ebene"]
sensors[IFM / Montronix Sensors]@{shape: processes}
dacq["Datenerfassung<br>(Edge Device)"]@{shape: }
sensors --> dacq
end
subgraph cloudSub["IT-Ebene"]
subgraph Moneo[Moneo]
MonInflux["Time Series Database<br>(InfluxDB)"]@{shape: cylinder}
OPCUA["OPC UA Interface"]
end
subgraph DataProc[Preprocessing+Connectivity]
DataLake[Bereinigte Datenspeicherung]@{shape: cylinder}
RTInterface["Echtzeit-Datenschnittstelle"]
end
RTInterface -->|Preprocessing & Bereinigung| DataLake
dacq -->|Stream| RTInterface
MLPipeline[ML Training Pipeline]
Analytics["Analytics Engine<br>(Anomaly Detection, RUL Prediction)"]
Dashboard[Dashboard & Alarme]
end
subgraph sewSub["Wartungsteam"]
edgeSub[Wartungspersonal]@{shape: bolt}
end
sensors --> Moneo
DataLake --> MLPipeline
MLPipeline -->|Aktualisierte Modelle| Analytics
DataLake -->|Historische Daten| Analytics
RTInterface -->|Echtzeit-Daten| Analytics
Analytics --> Dashboard
Dashboard -->|Alarme| edgeSub
sensorSub:::primaryBackground
edgeSub:::primaryBackground
cloudSub:::primaryBackground
sewSub:::primaryBackground
DataProc:::defaultBackground
Moneo:::defaultBackground
classDef sensor stroke:#0277bd,stroke-width:2px,fill:none
classDef moneo stroke:#7b1fa2,stroke-width:2px,fill:none
classDef cloud stroke:#388e3c,stroke-width:2px,fill:none
class sensors sensor
class OPCUA,MonInflux moneo
class DataLake,MLPipeline,Analytics,Dashboard,RTInterface cloudIT Systeme können entweder on-premise auf einer virtuellen Maschine deployt werden, oder ein SEW's Cloud Umgebung. Folgende Funktionen müssen bereitgestellt werden:
- Langfristige Datenspeicherung und Trendanalyse
- ML-Modelltraining auf historischen Daten
- Flottenweite Analytics über mehrere Maschinen
- Optimierung der Predictive-Maintenance-Planung
Die ML Modelle werden voraussichtlich folgende Algorithmen verwenden:
- Anomaly Detection mit Autoencodern, LSTMs, Random Forests, XGBoost etc.
- Remaining Useful Life (RUL) Prediction mit CNNs, LSTMs, Transformers etc.
- Pattern Recognition für spezifische Ausfallmodi (z.B. Bearing Wear, operative Probleme)
- Physical Simulation gekoppelt mit Machine-Learning-Algorithmus
Vorgehen
Das Projekt beginnt mit einer ersten explorativen Phase, die sich auf das Verständnis der aktuellen Spindel-Wartungsabläufe konzentriert, wichtige Ausfallmodi identifiziert und verfügbare Sensordaten erfasst & evaluiert. Diese Phase umfasst die Machbarkeitsanalyse und Entwicklung einer Proof-of-Concept-Pipeline für Anomaly Detection. Die gewonnenen Erkenntnisse leiten das Design und die Implementierung der Predictive-Maintenance-Lösung und stellen die Ausrichtung an operativen Anforderungen und technischen Anforderungen sicher.
Datenerfassung
Die Projektdauer hängt von der Geschwindigkeit der Datenerfassung ab. Das Training eines Machine-Learning-Modells zur Erkennung von Spindelausfällen erfordert Testdaten, die mehrere Ausfälle umfassen. Da Spindelausfälle relativ selten sind, kann es einige Zeit dauern, bis genügend Daten gesammelt sind.
Data Acquisition & Machbarkeitsstudie
Das Projektteam erfasst Daten, prüft deren Qualität und trainiert dann aktuelle State-of-the-Art Machine-Learning-Modelle auf diesen Daten. Da die Daten von zwei Spindeln mit bekannten Austausch-Events stammen, besteht das primäre Ziel darin, festzustellen, ob messbare Degradationsmuster vor Ausfällen existieren.
Der Ansatz beinhaltet eine explizite Machbarkeits-Phase, um zu bestätigen, dass verfügbare Daten prädiktive Degradationssignale enthalten, bevor die vollständige Modellentwicklung erfolgt.
Risiken:
| Risiko | Auswirkung | Mögliche Maßnahmen |
|---|---|---|
| Datenqualität der Sensoren ist nicht ausreichend | Mittel | Validierung der Sensorkalibrierung, Implementierung zusätzlicher Datenqualitätsprüfungen, Evaluation alternativer Sensoren (z.B. Montronix) |
| Spindelausfälle sind selten, der Datensatz enthält zu wenige "Nicht-iO" Signale um ein effektives Modell zu trainieren | Mittel | Verwendung von Anomaly-Detection-Ansätzen, Augmentierung mit synthetischen Daten, Transfer Learning von ähnlichen Systemen, längere Datenerfassungsphase |
| Technische Herausforderungen bei der Akquise von Rohdaten aus den existierenden Sensoren | Mittel | Nutzung von Edge-Geräten für direkte Sensoranbindung, Burst-Recording mit VSE100, Evaluation alternativer Sensoren (z.B. Montronix) |
Ergebnisse:
- Validierte ML-Modelle für Anomaly Detection und RUL Prediction
- Machbarkeitsbewertungsbericht mit Degradationsmuster-Analyse
- Alert-System-Konzept und Threshold-Empfehlungen
- Feature-Engineering-Dokumentation
- Wartungsrichtlinien basierend auf Model-Insights
Machbarkeitsprüfung
Nach dem Machbarkeits Meilenstein können SEW & Motius gemeinsam entscheiden, ob die verbleibenden Phasen basierend auf den Ergebnissen fortgesetzt werden sollen.
Motius schätzt Kosten von ca. 25.000€ für diese Machbarkeits-Phase.
Pilotsystem & Testing
Motius deployt und testet das Prediction System in einer kontrollierten Umgebung, während immer mehr rohe Sensordaten gesammelt werden, die für das Training fortgeschrittener Modelle verwendet werden können.
Grafana ist ein Open-Source Data-Visualization-Tool zur Exploration roher Daten, Anzeige von Modellvorhersagen und Versendung von Alarmen
Ergebnisse:
- Pilotsystem in SEW's Infrastruktur
- Real-time Data-Ingestion-Pipeline von rohen Sensordaten
- User-Dashboard mit Monitoring- und Alerting-Fähigkeiten
- Pilottest-Bericht mit Performance-Metriken und User-Feedback
- System-Dokumentation und technische Spezifikationen
Rollout & Validation
Mit den Erkenntnissen aus der Pilotphase geht das Projektteam zum vollständigen Deployment auf der Fertigungsfläche über. SEW muss die Maschinen mit den notwendigen Sensoren ausstatten, während Motius das IT-Deployment unterstützt, die Modellverfeinerung fortsetzt und bei Bedarf zusätzliche Hardware für Edge Computing bereitstellt.
MLFlow verwaltet den Machine-Learning-Lifecycle, einschließlich Experimente, Reproduzierbarkeit, Deployment und ein zentrales Model-Registry
Ergebnisse:
- Vollständig operatives Produktionssystem deployed auf der Fertigungsfläche
- Operative Verfahren und Wartungsprotokolle
- Continuous-Improvement-Prozess und Model-Monitoring-Framework
- Finaler Projektbericht mit Performance-Validierungsergebnissen
Roadmap
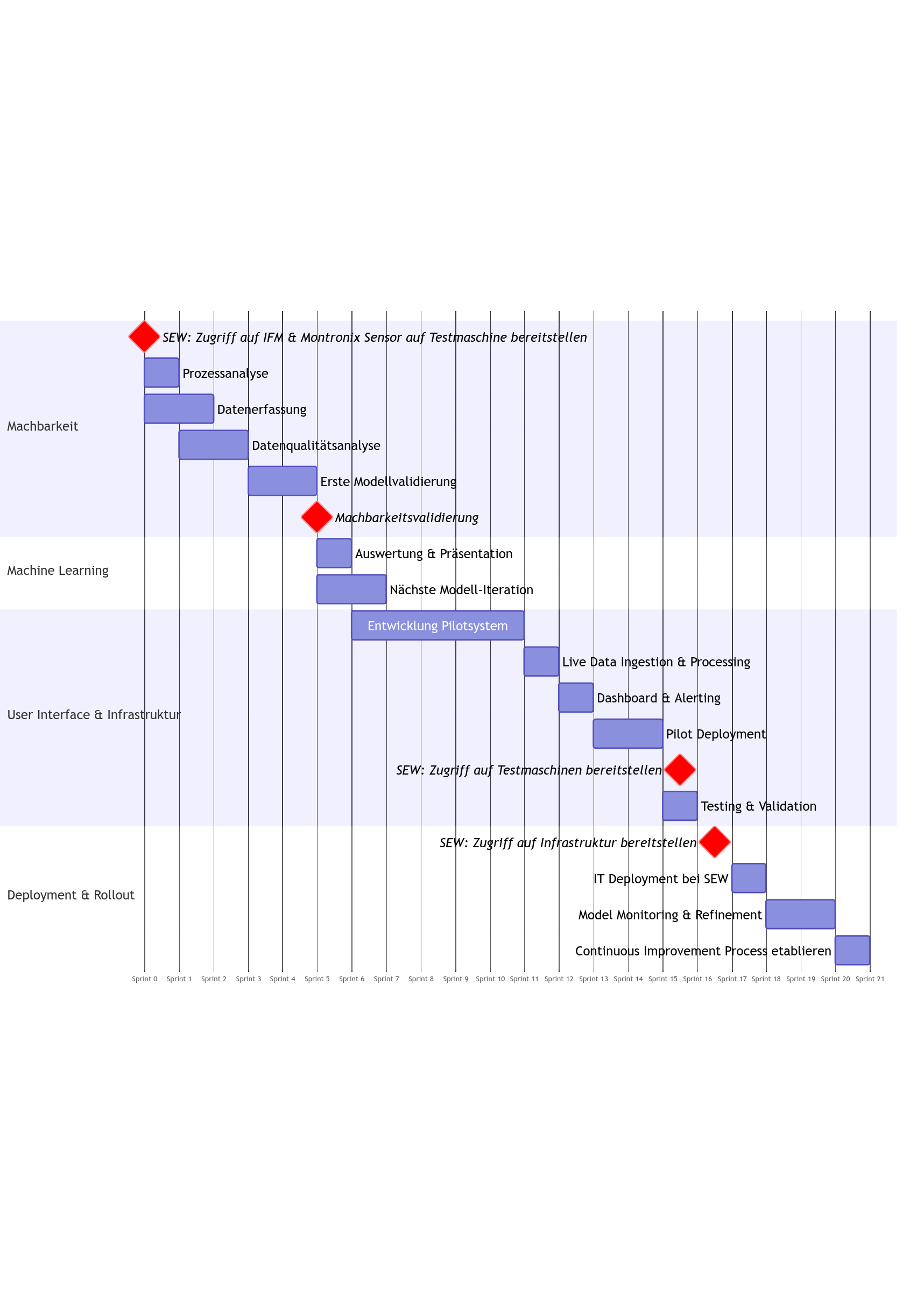
Arbeitspakete
| Arbeitspaket | Dauer |
|---|---|
| Literaturrecherche | 2 Tage |
| Data Loading & Cleaning Setup | 2 Tage |
| Sampling-Analyse & Datenqualitätsbericht | 2 Tage |
| Datentrennung & Failure Mapping | 1.5 Tage |
| RUL Label-Erstellung | 1 Tage |
| Feature-Trend-Visualisierung | 2 Tage |
| Vergleich vor/nach Austausch | 2 Tage |
| Signal-Korrelationsstudie | 1.5 Tage |
| Feature-Stabilitäts- & Degradationsprüfung | 1.5 Tage |
| Predictive Signal-Bewertung | 1.5 Tage |
| Rolling Window Feature Engineering | 2 Tage |
| Frequency-Domain Feature Engineering | 2 Tage |
| Feature Aggregation & Normalization | 1.5 Tage |
| Analyse und Lösungs-/Paper-Auswahl | 2 Tage |
| Baseline RUL Modeling basierend auf CNC Papers | 5 Tage |
| Validation Pipeline-Implementierung | 2 Tage |
| Model Validation & Metriken | 2 Tage |
| Sequence Model Prototyping | 3 Tage |
| Ergebnisse, Dokumentation, Präsentation | 2 Tage |
| High Resolution Data Streaming | 8 Tage |
| Machbarkeit: Monitor Data Acquisition | 3 Tage |
| Historischer Datenzugang einrichten | 2.5 Tage |
| Real-time Data Ingestion | 4 Tage |
| Data Validation Pipeline | 3 Tage |
| Infrastruktur Setup: Environment | 4 Tage |
| Infrastruktur Setup: Database Deployment | 3 Tage |
| Infrastruktur Setup: Backend API-Entwicklung | 9 Tage |
| Infrastruktur Setup: Network/VPN-Konfiguration | 2 Tage |
| Infrastruktur Setup: Monitoring & Logging | 2 Tage |
| Dashboard-Entwicklung: Infrastructure | 1 Tage |
| Dashboard-Entwicklung: Historische Trend-Ansichten | 2 Tage |
| Dashboard-Entwicklung: Alerting | 2 Tage |
| Pilotsystem & Validation: End-to-end Testing | 3 Tage |
| Pilotsystem & Validation: Performance Validation | 3 Tage |
| Pilotsystem & Validation: Dokumentation | 3 Tage |
| Rollout: ML Model-Iteration | 6 Tage |
| Rollout: Alert-Schwellenwerte anpassen | 1.5 Tage |
| Rollout: Model Performance Monitoring | 1 Tage |
| Rollout: System Deployment | 6 Tage |
| Rollout: Production Monitoring konfigurieren | 3 Tage |
| Meetings & Projektmanagement | 13 Tage |
| Gesamtdauer | 123.5 Tage |
Rollen und Kosten
| Rolle | Level | Tagessatz | Tage | Gesamtkosten |
|---|---|---|---|---|
| ML Engineer | Technology Specialist IV | 1,120.00 € | 48.00 Tage | 53,760.00 € |
| Senior Software Engineer | Technology Specialist IV | 1,120.00 € | 72.50 Tage | 81,200.00 € |
| Project Owner | Project Management IV | 1,344.00 € | 3.00 Tage | 4,032.00 € |
| Gesamtkosten Entwicklung | 138,992.00 € | |||
| Reisekosten | 12,186.97 € | |||
| Fixkosten | 2,500.00 € | |||
| Gesamtkosten Netto | 153,678.97 € | |||
| Steuer (19%) | 29,199.00 € | |||
| Gesamtkosten Brutto | 182,877.98 € | |||
Kosten für Machbarkeitsstudie
| Rolle | Level | Tagessatz | Tage | Gesamtkosten |
|---|---|---|---|---|
| ML Engineer | Technology Specialist IV | 1,120.00 € | 15.50 Tage | 17,360.00 € |
| Senior Software Engineer | Technology Specialist IV | 1,120.00 € | 4.00 Tage | 4,480.00 € |
| Project Owner | Project Management IV | 1,344.00 € | 3.00 Tage | 4,032.00 € |
| Gesamtkosten Entwicklung | 25,872.00 € | |||
| Reisekosten | 2,530.80 € | |||
| Fixkosten | 500.00 € | |||
| Gesamtkosten Netto | 28,902.80 € | |||
| Steuer (19%) | 5,491.53 € | |||
| Gesamtkosten Brutto | 34,394.33 € | |||
Rate Card
Es gilt die Rate Card aus dem Rahmenvertrag, Stand 2025:
| Bereich | Titel | Level | Stundensatz | Tagessatz |
|---|---|---|---|---|
| Technology Specialist | Senior Lead Tech Specialist | Technology Specialist VI | 180.00 € | 1,440.00 € |
| Lead Tech Specialist | Technology Specialist V | 161.00 € | 1,288.00 € | |
| Senior Tech Specialist | Technology Specialist IV | 140.00 € | 1,120.00 € | |
| Tech Specialist | Technology Specialist III | 126.00 € | 1,008.00 € | |
| Associate Tech Specialist | Technology Specialist III | 112.00 € | 896.00 € | |
| Developer | Technology Specialist I | 84.00 € | 672.00 € | |
| Project Management | Partner | Project Management VI | 230.00 € | 1,840.00 € |
| Senior Technical Executive | Project Management V | 187.00 € | 1,496.00 € | |
| Technical Executive | Project Management IV | 168.00 € | 1,344.00 € | |
| Senior Project Owner | Project Management III | 149.00 € | 1,192.00 € | |
| Project Owner | Project Management II | 133.00 € | 1,064.00 € | |
| Associate Project Owner | Project Management I | 112.00 € | 896.00 € |
Die oben skizzierten Projektrollen stellen ein Referenzteam dar. Sollte es bei der Besetzung der Projektrollen zu Abweichungen kommen, gilt folgende Rate Card. Das Projektvolumen bleibt unberührt.
ROI-Berechnung
Parameter
ROI-Analyse